attente — Simulateur de files d’attente¶
Je raconte chaque année à mes élèves que lorsque j’étais adolescent, il y avait dans les gares SNCF une file d’attente par guichet. J’ai vu cette organisation évoluer, et maintenant, les gares ont (presque ?) toutes une seule file d’attente, et les usagers sont redirigés au dernier moment vers un guichet de libre.
En étudiant des données (factices), je leur fait alors comprendre la raison (du moins, celle que je suppose) : avec plusieurs ou une seule file d’attente, le temps moyen d’attente est le même, mais l’écart-type est plus faible avec une seule file.
J’ai fait cette simulation de file d’attente pour observer cette différence.
Simulations¶
Le logiciel simule l’arrivée d’usagers dans une salle, (avec un temps entre deux arrivées défini par une loi de probabilité donnée). Ces usagers choisissent une file selon une certaine stratégie, puis ils attendent. À leur tour (le choix de la personne suivante dans une file étant configurable) ils s’avancent au guichet (ce qui dure un certain temps défini par une autre loi de probabilité) avant de partir.
Il y a autant de paramètre car (1) cela m’amusait, et (2) les files d’attentes sont aussi utilisées en informatique, et les différentes stratégies présentées ici peuvent alors avoir leur intérêt.
Les différents paramètres sont :
Le nombre d’usagers, de files et de guichets.
La loi de probabilité définissant la durée entre deux arrivées d’usagers. Une loi exponentielle est réaliste.
La loi de probabilité définissant la durée du service (le temps que va passer l’usager au guichet).
La stratégie avec laquelle l’usager choisit sa file d’attente :
la file la plus courte en nombre de personnes (ce qui constitue une stratégie réaliste) ;
la file la plus courte en temps (en prenant en compte le temps allant être passé au guichet par les usagers de la file, ce qui correspond à un usager omniscient). Cette stratégie ne prend pas compte du nombre de guichets, ou du temps restant aux usagers présents au guichet, parce que j’avais la flemme ;
un choix au hasard.
La stratégie utilisée pour choisir le prochain usager dans une file :
premier arrivé, premier servi (appelé « file » en informatique, comme au cinéma, dans un magasin, dans une gare, etc.) ;
dernier arrivé, premier servi (appelé « pile » en informatique, comme une pile d’assiettes) ;
l’usager le plus rapide passe en premier (c’est la version extrême où chaque usager dans la file est poli, et laisse passer devant lui quelqu’un qui va être plus rapide) ;
l’usager le plus lent passe en premier (l’inverse de la précédente) ;
au hasard.
Le nombre initial de personnes dans chaque file (pour ne pas prendre en compte le début de la simulation, où il n’y a pas encore de queue et les usagers vont directement au guichet).
Si les usagers sont autorisés à changer de file (car un guichet est libre, et sa file d’attente est vide), ou non.
Le type d’affichage (moyenne et écart-type ; médiane et écart interquartile ; liste brute des temps d’attente ; ou animation dans le terminal avec des emojis).

Fig. 1 Les deux premiers guichets partagent une file, de même que les deux suivants. Le dernier guichet a sa propre file.¶
Analyse des simulation¶
Gares SNCF¶
Pour la gare SNCF, avec un millions d’usagers servis par cinq quichets, nous obtenons les résultats suivants.
· |
Nombre de files |
|
|---|---|---|
· |
1 |
5 |
Moyenne |
14.309613 |
14.309613 |
Écart-type |
19.776223 |
21.482701 |
Ceci est cohérent avec ce que j’enseigne à mes élève, car la moyenne du temps d’attente est la même (ce qui est logique, en étudiant le problème en regardant combien de personnes passent par les guichets sans faire attention à l’organisation des files d’attente), et l’écart-type est plus petit avec une file partagée qu’avec cinq files.
Ceci n’est pas cohérent avec que je j’enseigne à mes élèves, pour deux raisons. D’une part, les statistiques (moyenne et écart-type) sont très variables d’une simulation à l’autre : la différence d’écart-type entre deux simulations aux mêmes paramètres peut être bien plus grande que la différence d’écart-type entre deux simulations aux nombres de files différents, sauf à prendre un très grand nombre d’usagers (un million, et encore…), ce qui n’est pas réaliste. D’autre part, la différence d’écart-type est assez faible, si bien que je me demande si cela justifie à elle seule le changement de type de files que j’ai observé depuis une vingtaine d’années…
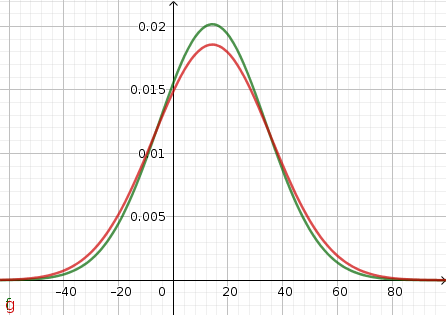
Fig. 2 En rouge, la densité de probabilité de la loi normale avec la moyenne et écart-type observés avec une file par guichet ; en vert, avec une file partagée pour tous les guichets.¶
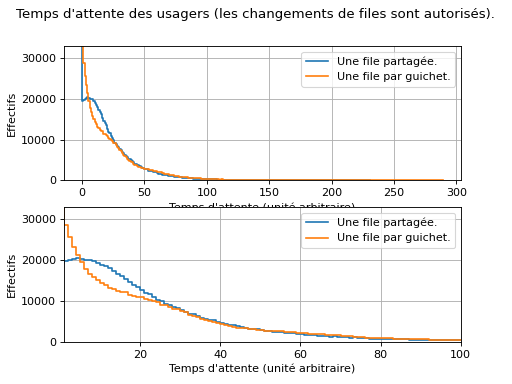
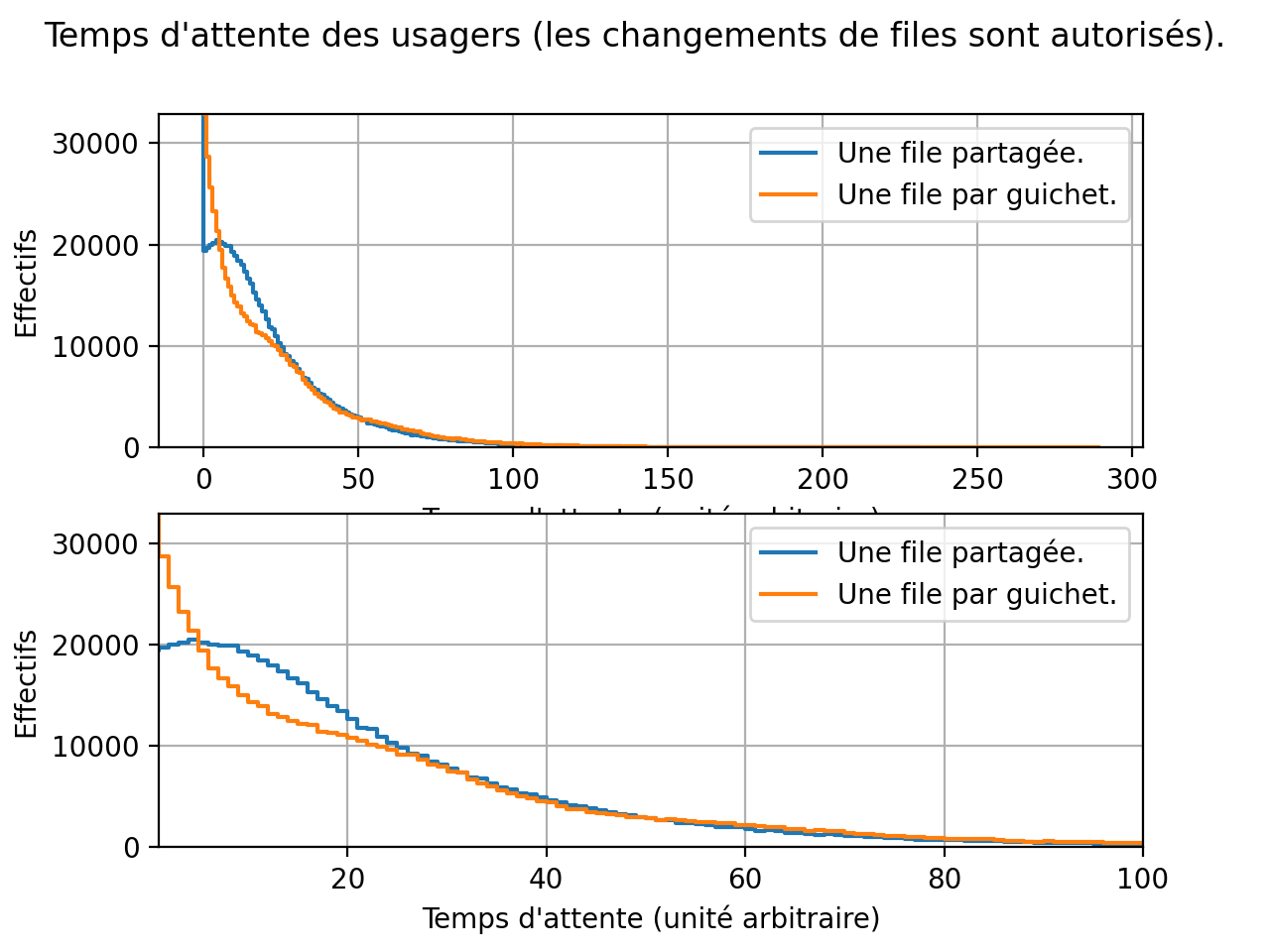
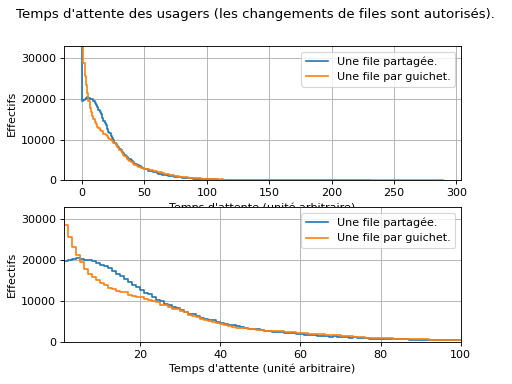
L’histogramme suivant (la version du bas est un zoom sur celle du haut) représente les effectifs des temps d’attente dans les deux cas. On observe :
qu’avec une file partagée, il y a moins de très courts temps d’attente (ces très courts temps d’attente observés plutôt avec une file par guichet correspond aux usagers qui ont la chance de tomber dans la bonne file) ;
qu’avec une file partagée, il y a (un tout petit peu) mouns de très long temps d’attente (ces longs temps d’attente observés avec une file par guichet correspond aux usagers qui ont la malchance de tomber dans la mauvaise file) ;
qu’avec une file partagée, davantage d’usagers ont des temps d’attente moyen.
{kind=link}
{kind=link}
La mauvaise file¶
Une autre interprétation à cette évolution du nombre de files d’attente (d’une file partagée, à une file par guichets) peut aussi s’expliquer par une analyse individuelle de la situation : on a toujours l’impression d’être dans la mauvaise file.
À moins d’être sur un bord, un usager dans une file observe deux files : à sa gauche ou à sa droite. Avec sa propre file, il a donc trois files à comparer. La situation étant équiprobable, il y a une chance sur trois que l’usager soit dans la file la plus rapide des trois. Il a donc deux chances sur trois (plus de la moitié) d’observer qu’une des files voisines va plus vite que la sienne. Ajoutons à cela : un peu de mauvaise fois, et le biais de confirmation, et les usagers peuvent avoir l’impression d’être toujours dans la mauvaise file !
Sans considération complexes de moyenne et d’écart-type, une seule file pour l’ensemble des guichets permet de supprimer cette (fausse) impression d’être dans la mauvaise file.
Autres cas¶
Voici quelques comparaisons..
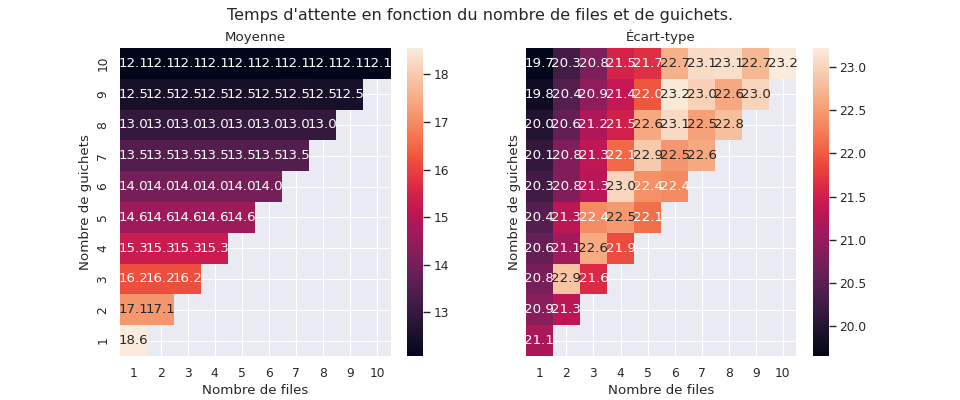
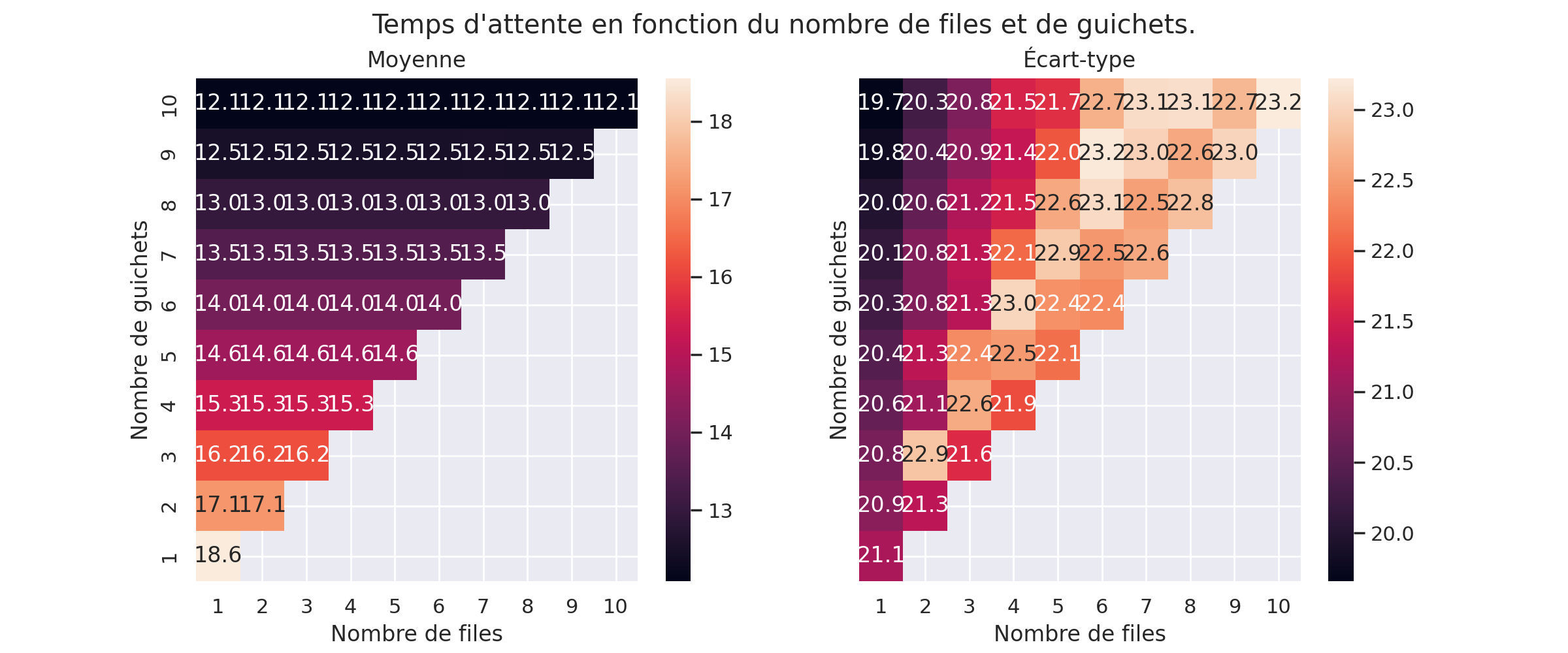
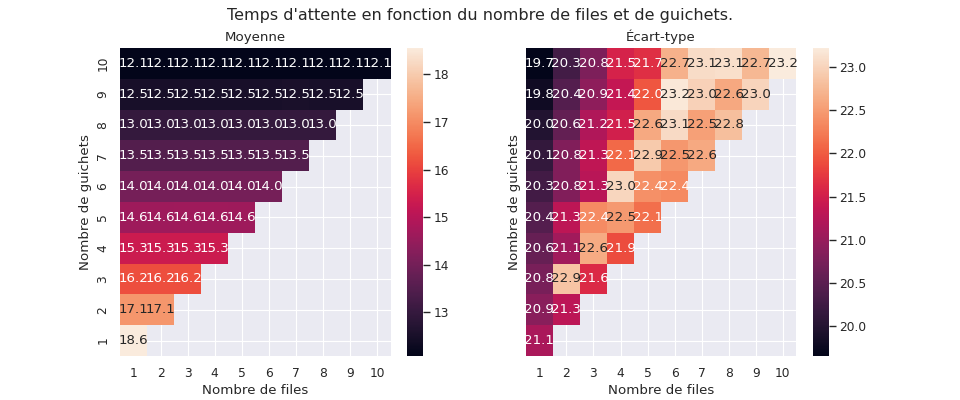
La première compare les moyennes et écart-type avec plus ou moins de guichets et plus ou moins de files. Les paramêtres sont les mêmes, sauf la loi de probabilité définissant le temps de service (le temps passé au guichet), gui dépend du nombre de guichets (sans cela, la moyenne du temps d’attente devrait être logiquement deux fois moins longue avec deux fois plus de guichets). Les comparaisons doivent donc plutôt se faire en ligne qu’en colonnes.
Comme précédemment, nous observons que le temps d’attente moyen ne dépond pas du nombre de files. En revanche, globalement, à nombre de guichets égal, plus il y a de files d’attente, plus l’écart-type est élevé.
{kind=link}
{kind=link}
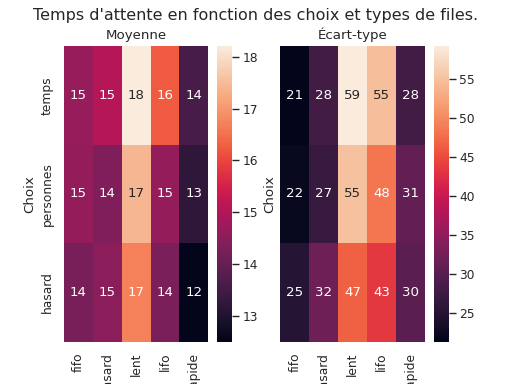
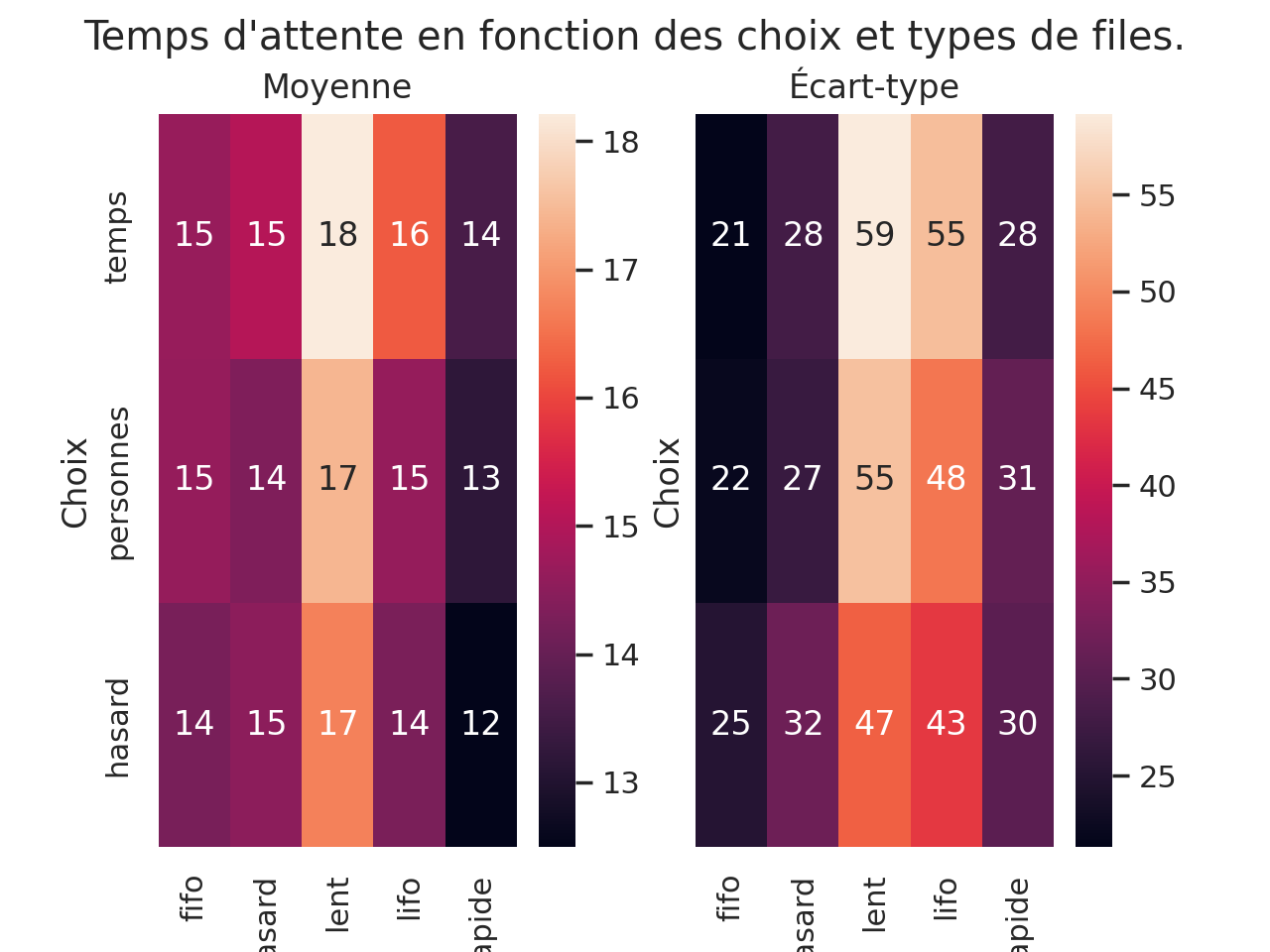
Le graphique suivant compare les différentes stratégies. Ici, à part les stratégies de choix de file et de choix de la personne suivante dans une file, tous les paramêtres sont les mêmes.
Je ne sais pas trop comment interpréter ce graphique. J’ai l’impression qu’à discipline (choix de la prochaine personne dans la file), la meilleure stratégie globale de choix de file est le hasard ! Ce qui me surprend ; j’aurais pensé que les moyennes seraient identiques…
{kind=link}
{kind=link}
Programme¶
Simulation de files d’attente
usage: attente [-h] [--version] [-g GUICHETS] [-u USAGERS] [-f FILES]
[-r RANDOM] [-a ARRIVEE] [-s SERVICE] [-c CHOIX]
[-d DISCIPLINE] [-o SORTIE] [-i INITIAL] [-C CHANGEMENT]
Named Arguments¶
- --version
show program’s version number and exit
- -g, --guichets
Nombre de guichets (défaut : 5).
Default: 5
- -u, --usagers
Nombre d’usagers (défaut : 1000).
Default: 1000
- -f, --files
Nombre de files d’attente (doit être inférieur ou égal au nombre de guichets ; défaut : 3).
Default: 3
- -r, --random
Graine du générateur aléatoire (la même graine génèrera les mêmes usagers).
- -a, --arrivee
Loi de probabilité définissant l’arrivée d’un nouvel usager (depuis l’ancien). - constante : Renvoit toujours la même valeur (celle donnée en argument). - exp : Loi de probabilité exponentielle (arguments : « moyenne »). - normale : Loi de probabilité normale (arguments : « moyenne:écart-type »). - uniforme : Loi de probabilité uniforme (arguments : « min:max »).
Default: exp:7
- -s, --service
Loi de probabilité définissant la durée du service. - constante : Renvoit toujours la même valeur (celle donnée en argument). - exp : Loi de probabilité exponentielle (arguments : « moyenne »). - normale : Loi de probabilité normale (arguments : « moyenne:écart-type »). - uniforme : Loi de probabilité uniforme (arguments : « min:max »).
Default: normale:30:10
- -c, --choix
Algorithme de choix d’une file par un usager. - hasard : Choix d’une file au hasard. - personnes : File la plus courte en nombre de personnes. - temps : File la plus courte en temps d’attente.
Default: personnes
- -d, --discipline
Algorithme de choix du prochain usager dans une file. - fifo : Premier arrivé, premier servi. - hasard : Une personne au hasard est choisie. - lent : Le plus lent passe en premier - lifo : Premier arrivé, dernier servi. - rapide : Le plus rapide passe en premier
Default: fifo
- -o, --output
Type de données à afficher. - attente : Affiche la liste des temps d’attente - mediane : Médiane et Écart interquartile - moyenne : Moyenne et Écart-type - unicode : Tracé des files d’attente en unicode (argument: temps d’attente).
Default: moyenne
- -i, --initial
Nombre d’usagers dans chaque file au début de la simulation. Ces usagers ne sont pas comptabilisés dans les statistiques.
Default: 0
- -C, --changement
Les usagers peuvent changer de file si un guichet est disponible.
Default: False